Download files using the Sharepoint API and Python
Before you start
- An Azure App has been created. If you haven't done so already, follow the instructions here.
- Install the Dataplane pip package (https://pypi.org/project/dataplane/) by adding
dataplaneto requirements.txt file. For further instructions, check how to Update Python packages under Docs > Getting Started > Create a data pipeline. - Sharepoint permissions assigned. Guidance to assign permissions here.
Overview
This recipe shows how to download an Excel file from Sharepoint and upload that file to PostgreSQL using Python Pandas Dataframes.
Download Excel using Sharepoint API and Python in Dataplane's code editor
If you are new to Dataplane, learn how to use Dataplane's code editor.
from dataplane import sharepoint_download
import os
# ----- Download the adjustment files from Share point -----
Host = os.environ["secret_dp_sharepoint_host"]
TenantID = os.environ["secret_dp_azure_tenant_id"]
ClientID = os.environ["secret_dp_azure_client_id"]
Secret = os.environ["secret_dp_azure_client_secret"]
# See screenshot below on how to set these inputs.
SiteName = "DataplaneDemo"
SharepointFilePath = "/InputFiles/adjustmentsdemo.xlsx"
rs = sharepoint_download(Host,
TenantID,
ClientID,
Secret,
SiteName,
SharepointFilePath,
DownloadMethod="Object", Library="root")
if rs["result"]!="OK":
print(rs)
# ------- Read the Excel file ----------
from pandas import read_excel
from io import BytesIO
# The entire contents of the Excel file are kept in memory without saving to disk and transferred to a Pandas dataframe.
df = read_excel(BytesIO(rs["content"]), index_col=0)
print(df)
# ------ Upload the Pandas dataframe into a PostgreSQL table ------
from sqlalchemy import create_engine
import os
# Reference your secrets
dbpwd = os.environ["secret_dp_postgresql_password"]
dbhost = os.environ["secret_dp_postgresql_host"]
dbuser = os.environ["secret_dp_postgresql_user"]
conn = create_engine(f"postgresql+psycopg2://{dbuser}:{dbpwd}@{dbhost}/analytics")
# This will replace the entire table named reportoutput on each run
df.to_sql('reportoutput', con=conn, index=False, if_exists="replace")
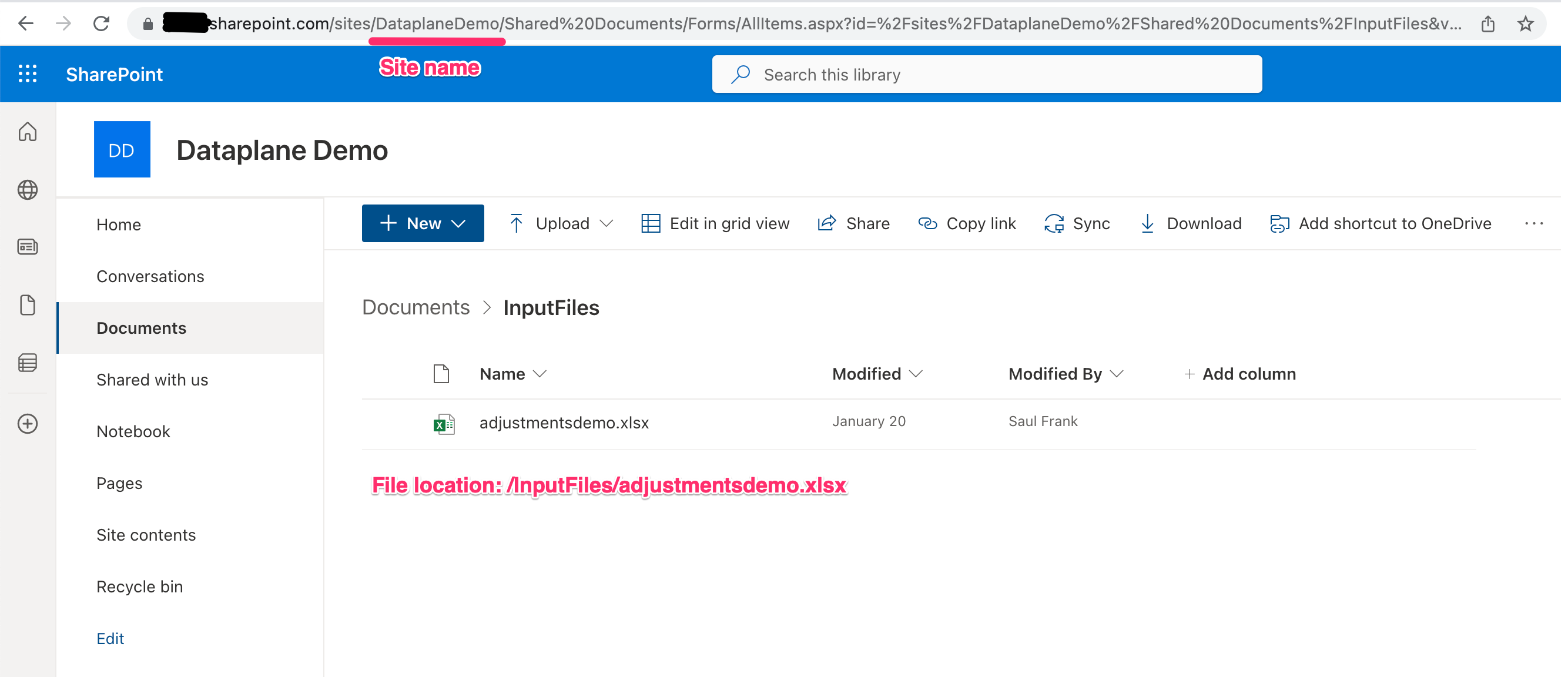
Where to get the site name and file path
SiteName = "DataplaneDemo"
SharepointFilePath = "/InputFiles/adjustmentsdemo.xlsx"