Use an API or a webhook setup to trigger a data pipeline
API triggers are a powerful way of running a pipeline or background processes from another server, process or even another data pipeline on Dataplane. For example, a server can send a webhook to Dataplane with json data. Dataplane can use that json data within the logic of a data pipeline.
Create a data pipeline with an API trigger
Go to Pipelines and click the Create button. See create a data pipeline.
Drag the API trigger onto the pipeline canvas as the first component of your data pipeline.
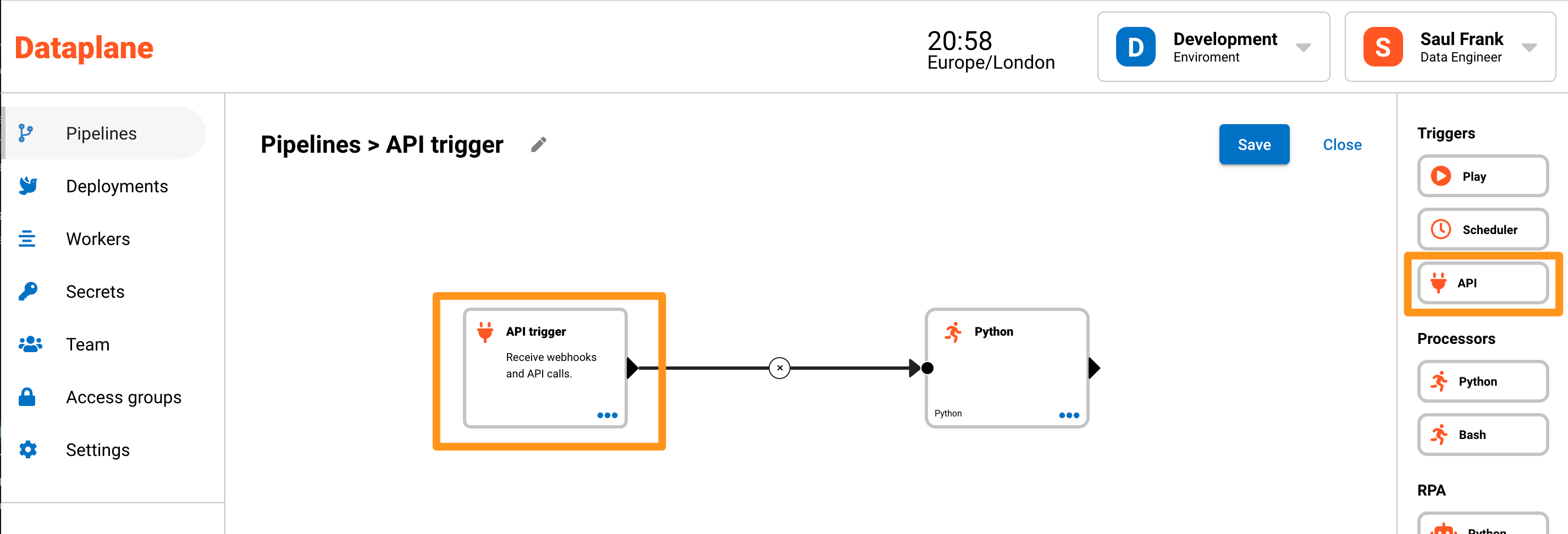
Configuring the API trigger
After dragging and dropping the API trigger component, a page opens to configure the API trigger. At any time, you can edit the API trigger by clicking the menu dots on the API trigger node and then clicking API in the menu as shown iin the image below.
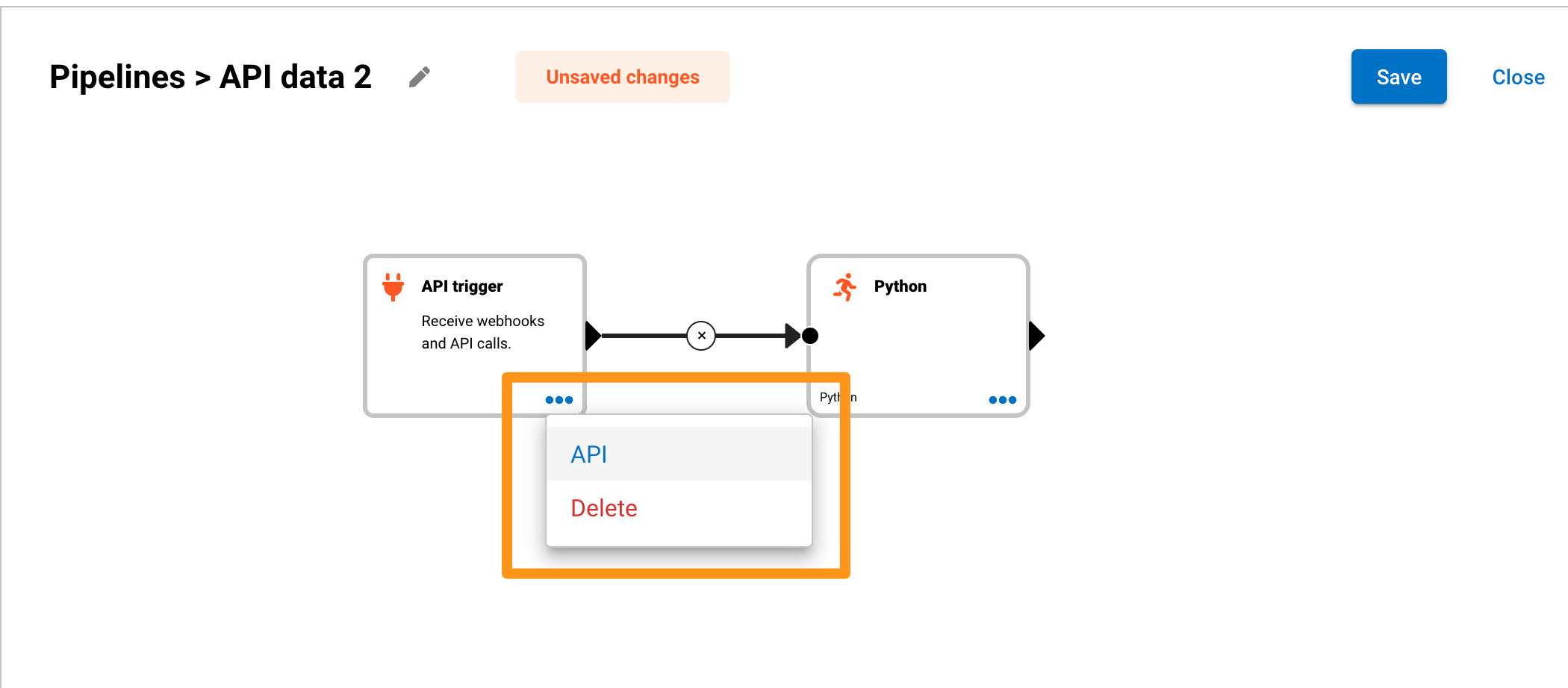
Private and public endpoints for the API trigger
To provide better options for security configurations, the API trigger has two endpoints. The private endpoint is used for internal communication between Dataplane components or from servers within a private network. The public endpoint is used for external communication from origins outside a private network. Using a network ingress, you can specifically configure outside access to the public endpoint at /publicapi/api-trigger/*.
Examples of cURL commands and python code to trigger the API trigger
When configuring an API trigger, Dataplane gives you examples of code that you can use. By clicking the See Example links next to either the private or public endpoints, you can see examples of cURL commands and Python code to send an API call or to configure the API trigger to receive webhooks.
This is an example of a cURL command that will trigger the API trigger and send json data.
curl --location --request POST 'https://{{ Dataplane host }}/publicapi/api-trigger/38f13ed3-6052-4db8-c162-091334cc7bfa' --header 'Content-Transfer-Encoding: application/json' --header 'Accept: text/plain' --header 'apikey: {{api key}}' --header 'Content-Type: application/json' --data-raw '{"key1":"value1"}'
The same python example is available when you click the Python tab.
import json, requests
# optional api key per settings
apikey = "{{api key}}"
# Publish Url
url = "https://{{ Dataplane host }}/publicapi/api-trigger/38f13ed3-6052-4db8-c162-091334cc7bfa"
# optional pay load
payload = {“key1”: “value1”}
headers= {
"DataplaneAuth": apikey,
'Content-type': 'application/json',
'Accept': 'text/plain'
}
response = requests.request("POST", url, headers=headers, data=payload)
status_code = response.status_code
print(str(status_code) + ": " + response.text)
By running either of these examples, you will trigger the data pipeline to run. You will see a successful run by going to the pipeline in the Dataplane platform.
Security keys
With Dataplane, you can secure your API trigger endpoint with security keys. This is useful when you want to restrict access to the API trigger, particularly when accessing a public endpoint from a location outside your private network.
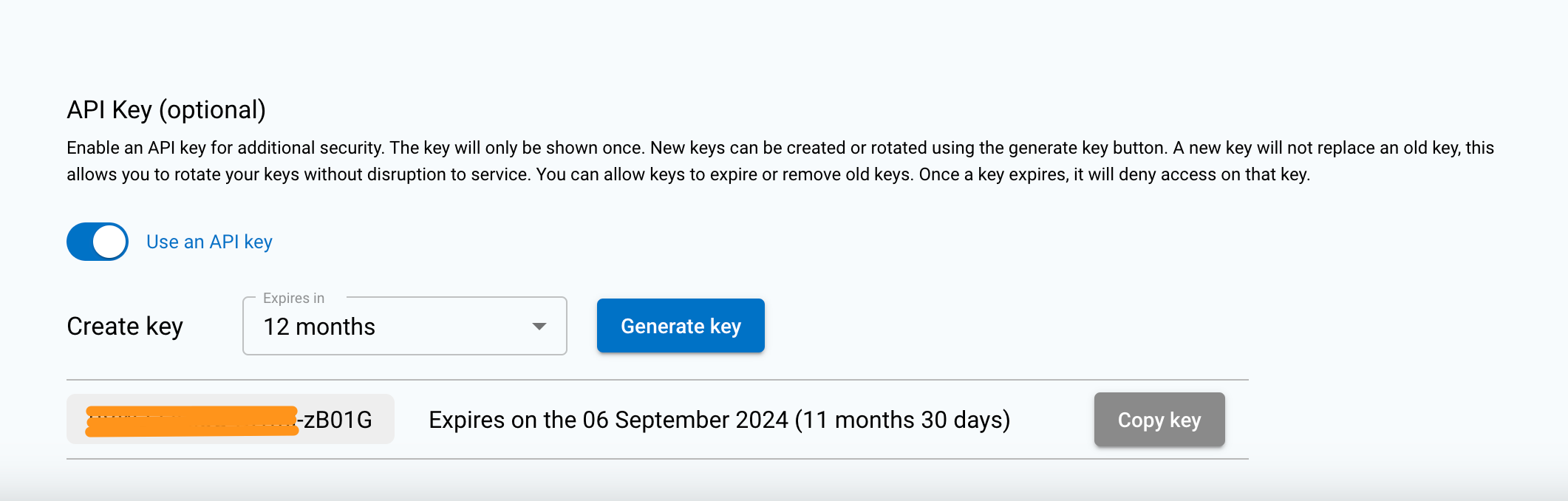
Steps to generate a security key
- Under the heading API Key (Optional), click the toggle to enable security keys.
- This will show an option to generate a security key.
- Set the expiry date and time for the security key.
- Click the Generate key button.
- The security key will only be shown once until navigated away from the page.
- Keep the security keys safe and secure, preferably using key manager.
It is best security practice to keep a short expiry date. This also means you will need to rotate the security keys more often. You can do this by putting a reminder in your calendar a week before the key's expiry date. Dataplane allows you to rotate the keys without having to interrupt services. This is done by adding a new key before the old key expires, updating the client with the new key and then deleting the old key on Dataplane.
Using data from the body of an API call
Using the example above to trigger a pipeline run, json data {"key1":"value1"} is sent in the body of the API call.
This data can be used in the pipeline by retrieving the environment variable DP_API_DATA.
Here is an example of how to use the data by loading the json data into a Python dictionary using a Dataplane Python processor.
import os, json
if __name__ == "__main__":
print("My data: "+os.environ["DP_API_DATA"])
x = json.loads(os.environ["DP_API_DATA"])
print(x["key1"])
This will Python code will print the following to the console.
My data: {"key1":"value1"}
value1
Mechanics of using the environment variable DP_API_DATA
Data Time To Live (TTL): The data is kept in memory for the TTL duration specified in the API trigger. The default TTL is 84600 seconds (24 hours). If you expect your pipeline to take longer than 24 hours, you should set a higher expiry in the API trigger configuration. If you are sending larger data with quicker pipeline run times, it is better to set a TTL less than 24 hours to avoid unnecessary memory build up.
Data size limit: The default size limit is 5MB. This is configured when configuring the API trigger. If you expect your data to be larger than 5MB, you should increase the size limit.
Unique to each run: The data is stored in Redis where the key of the data is unique to each run. If the pipeline is run again, the data will not be overwritten and will be kept for the configured TTL duration.
The data is accessible to each step in the pipeline during the run. This means you can use the data in multiple processors in the pipeline. This is only true if the TTL has not expired and the pipeline is still running.
When developing pipelines, you can use the replay ID of a previous run to test the input data from an API trigger. This is useful when you want to test the pipeline with the same data. You can find the replay ID in the pipeline run history in the code editor.